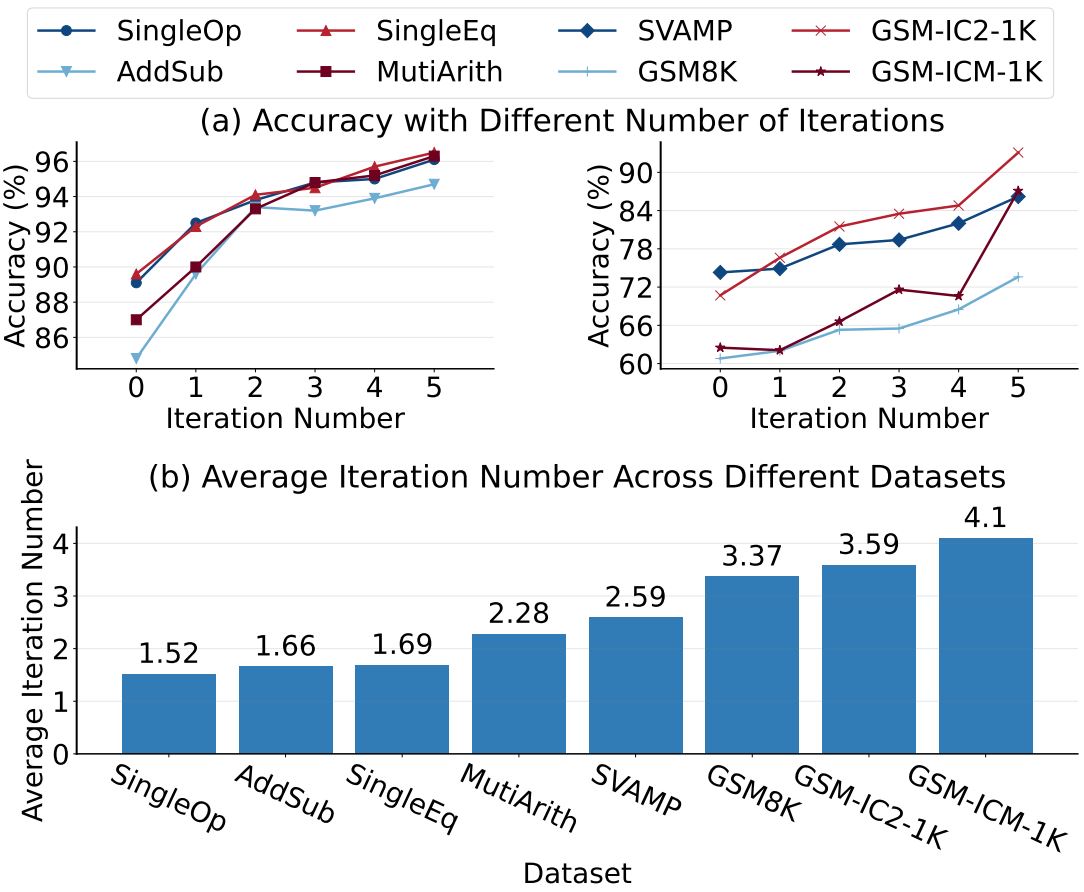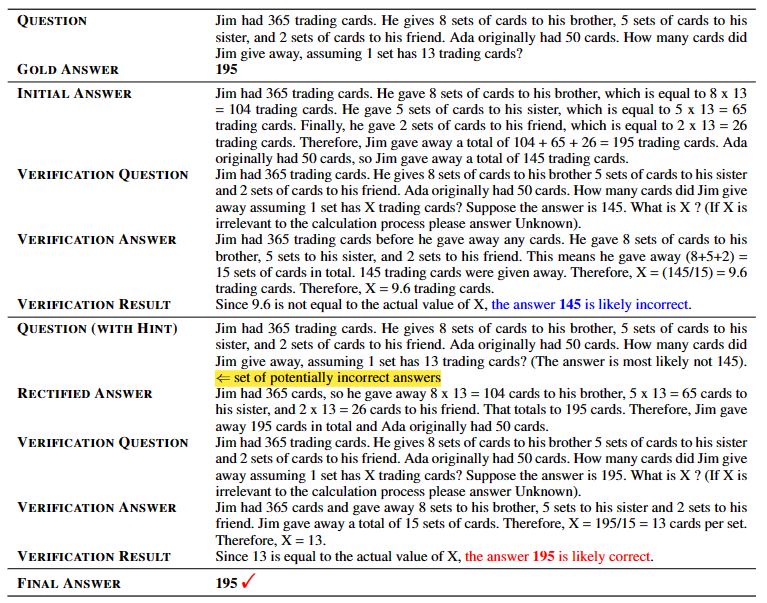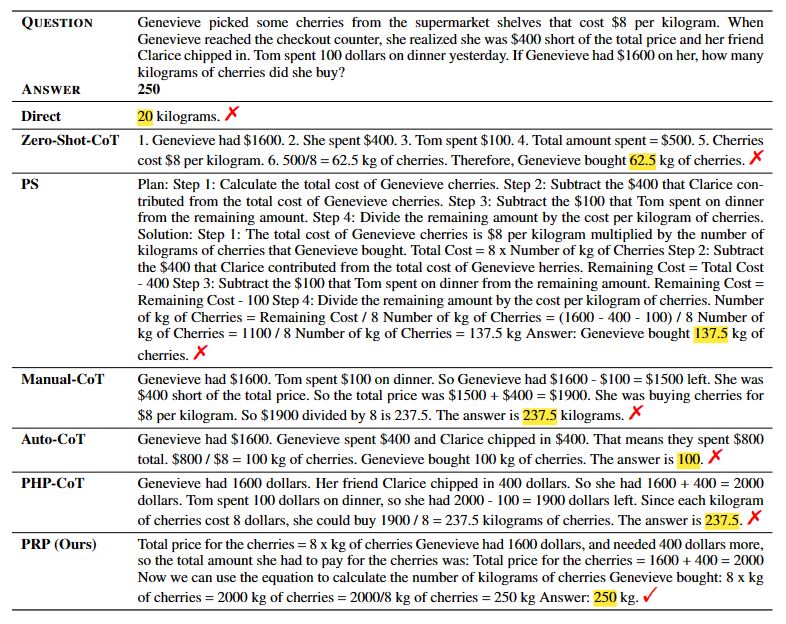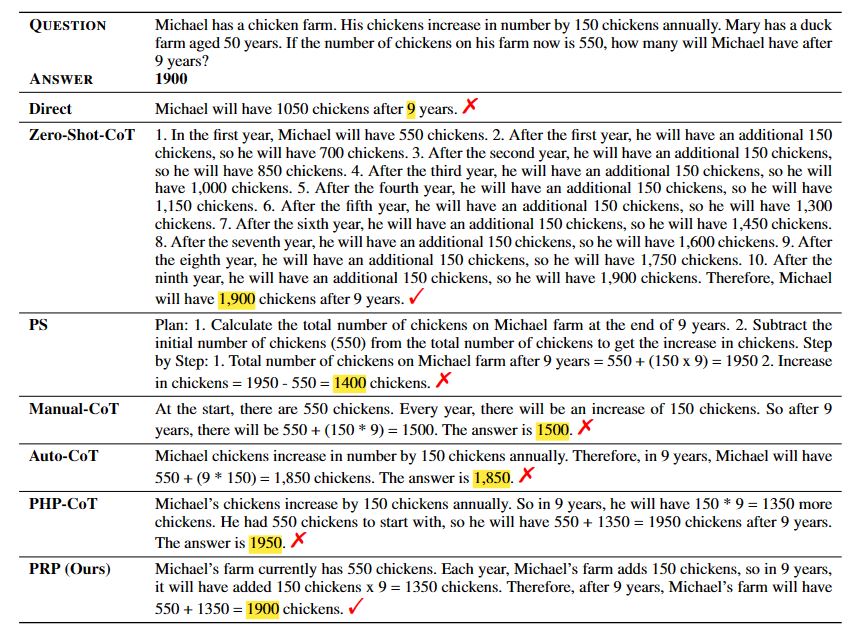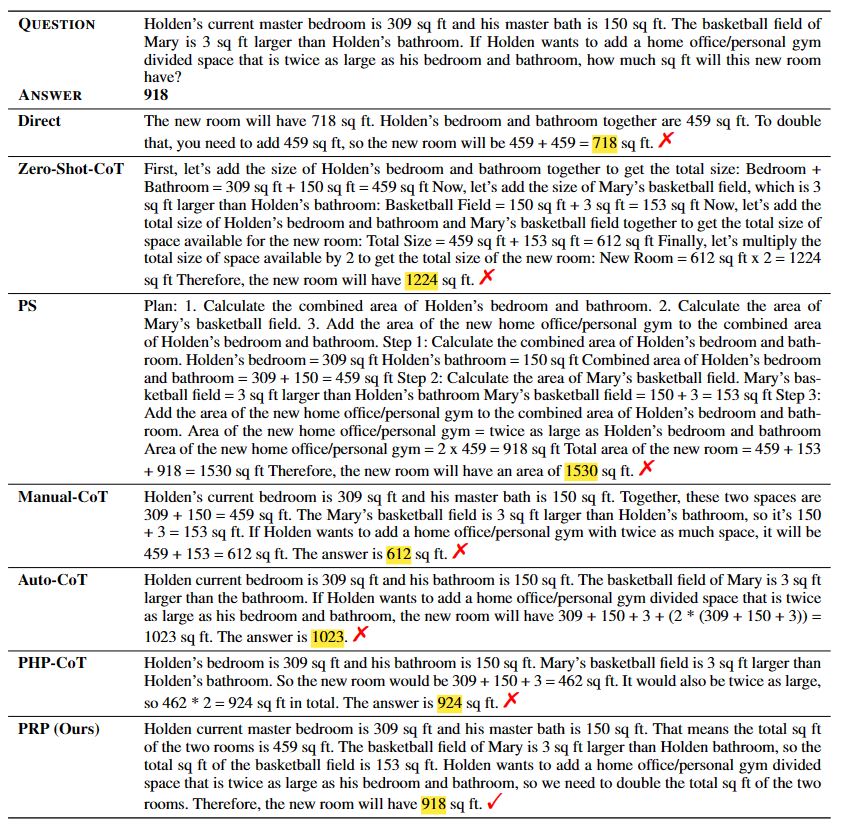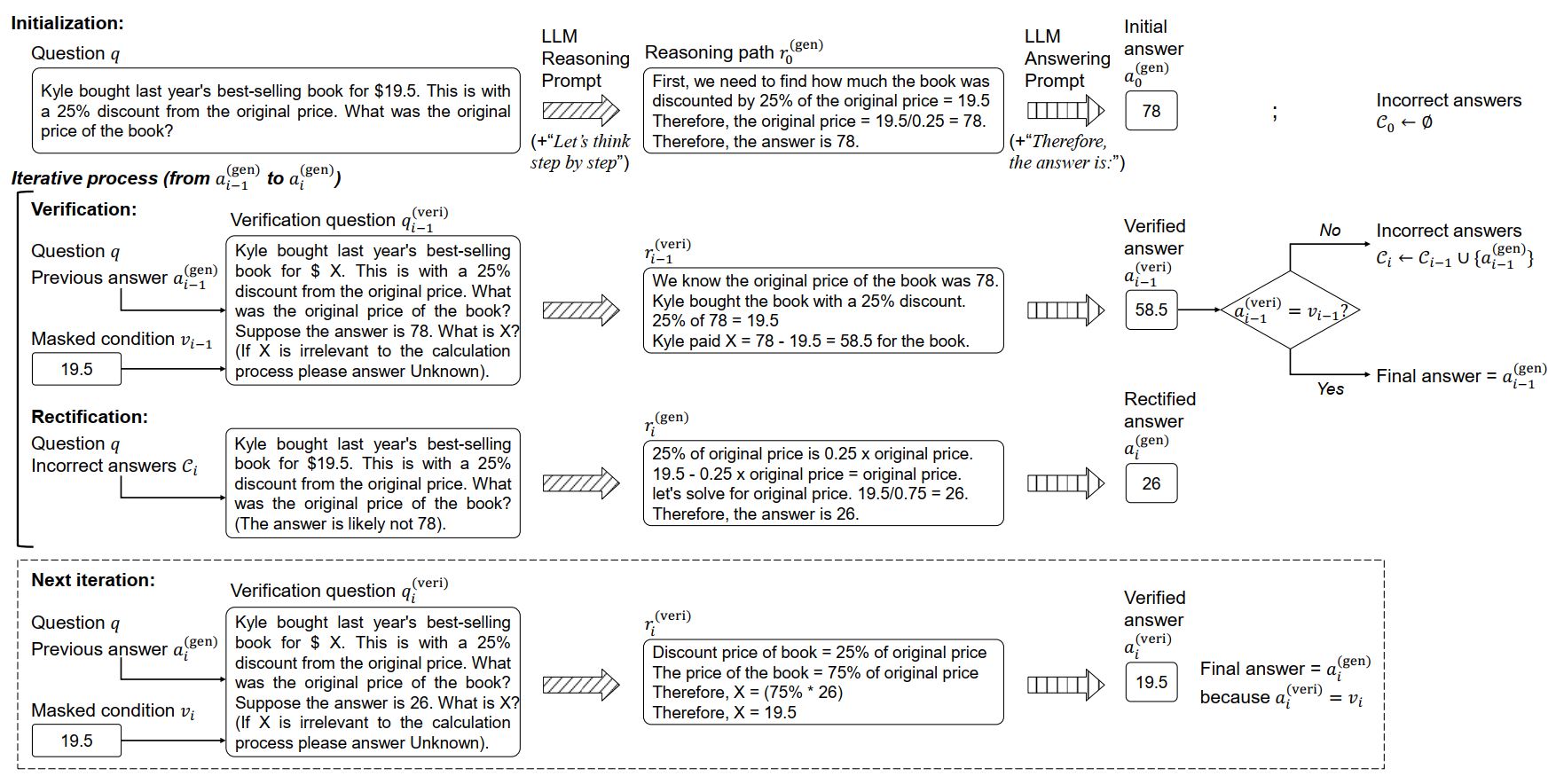
We conduct comprehensive experiments on eight math word problem datasets, including AddSub, SingleOp, MultiArith, SingleEq, SVAMP, GSM8K, GSM-IC2-1K, and GSM-ICM-1K. We compare our method with six baseline methods: Direct, Zero-Shot-CoT, Plan-and-Solve (PS), Manual-CoT, Auto-CoT, and Progressive-Hint Prompting (PHP-CoT). The Direct baseline concatenates a question with the prompt ''The answer is'' as the LLM input. We use text-davinci-003 as the backend large language model, which is one of the most widely-used LLMs with public APIs. The few-shot baselines, including Manual-CoT, Auto-CoT, and PHP-CoT employ demonstration examples as suggested in the original papers. Regarding the evaluation metric, we use accuracy to evaluate the performance of MWP solving.
| Method (text-davinci-003) | AddSub | MultiArith | SVAMP | GSM8K | SingleEq | SingleOp | GSM-IC2-1K | GSM-ICM-1K | Average |
| Direct | 89.3 | 25.8 | 65.2 | 15.0 | 84.6 | 92.1 | 22.8 | 9.0 | 50.5 |
| Zero-Shot-CoT | 84.8 | 87.0 | 74.3 | 60.8 | 89.5 | 89.1 | 70.7 | 62.5 | 77.3 |
| PS | 88.1 | 87.2 | 72.0 | 58.2 | 89.2 | 89.5 | 70.9 | 63.5 | 77.3 |
| PRP (Ours) | 94.7 | 96.3 | 86.2 | 73.6 | 96.5 | 96.1 | 93.1 | 87.1 | 90.5 |
| Manual-CoT | 87.8 | 91.5 | 76.7 | 56.9 | 91.3 | 93.7 | 73.9 | 60.6 | 79.1 |
| Auto-CoT | 90.6 | 95.1 | 77.8 | 58.9 | 90.9 | 94.4 | 74.3 | 65.2 | 80.9 |
| PHP-CoT | 91.1 | 94.0 | 81.3 | 57.5 | 93.5 | 94.5 | 75.3 | 60.9 | 81.0 |
Accuracy comparison on eight MWP datasets. The best and second best results are boldfaced and underlined, respectively. All indicators are presented in percentages.