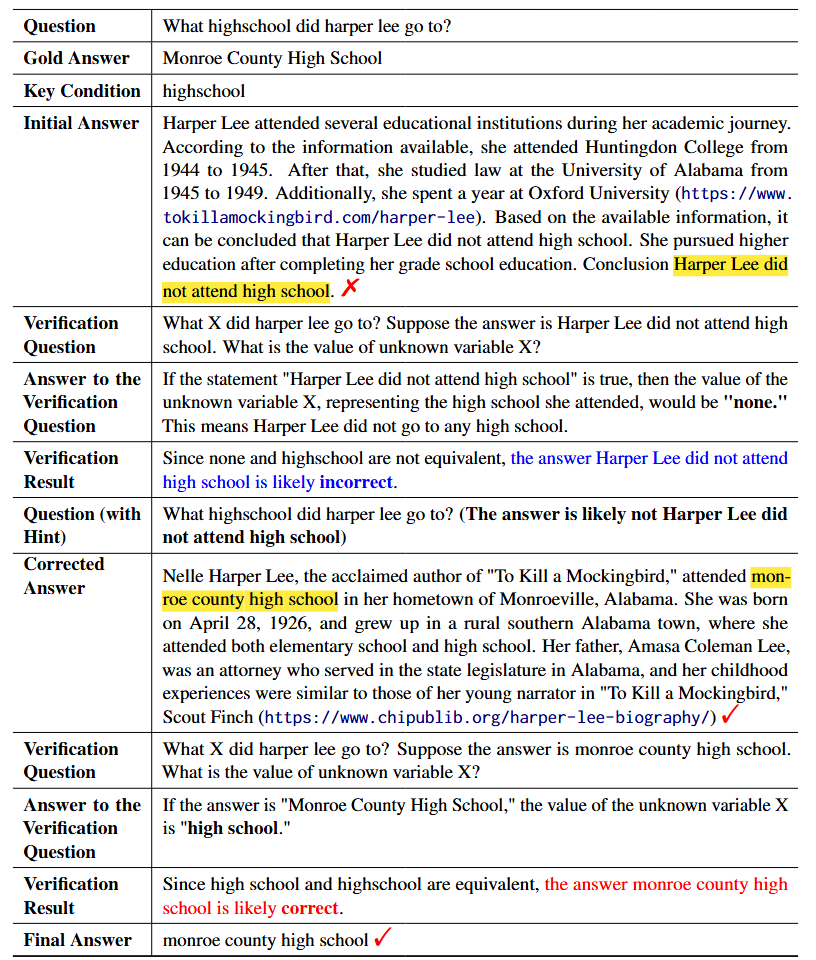
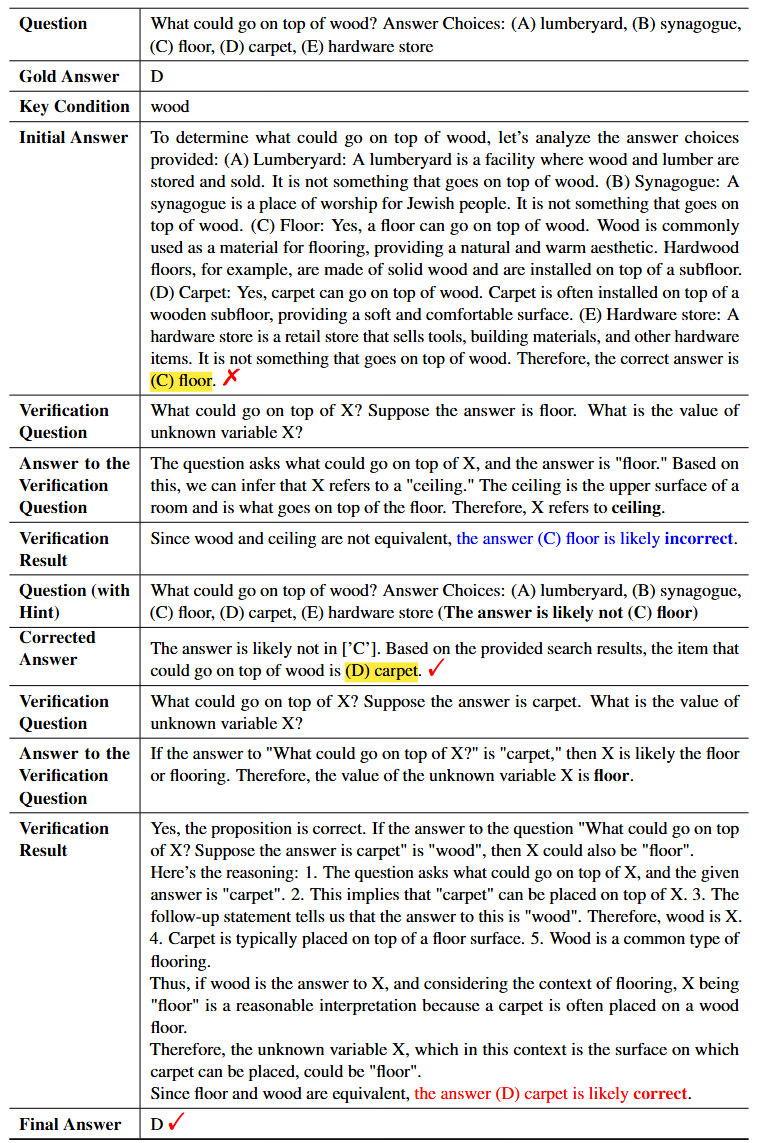
We evaluate ProCo on three complex reasoning tasks: arithmetic reasoning (GSM8K, AQuA, and MATH); open-domain question answering (NQ, TriviaQA, WebQ, and HotpotQA); and commonsense reasoning (CSQA). We compare ProCo with three types of baselines: (1) LLM-generated documents: GenRead. (2) Search engine-retrieved documents: RAG. (3) Without external documents: CoT, CoVe, and Self-Correct. All methods serve as baselines for open-domain question answering and commonsense reasoning tasks. For arithmetic reasoning, where external documents are unnecessary, CoT and Self-Correct are used. These baselines can be integrated into ProCo, for instance, using GenRead to generate an initial answer and ProCo to refine it (GenRead + ProCo).
| method | Open-domain Question Answering | Commonsense Reasoning |
Arithmetic Reasoning | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NQ | TriviaQA | WebQ | HotpotQA | CSQA | GSM8K | AQuA | MATH | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | Accuracy | Accuracy | Accuracy | Accuracy | |
| *Using LLMs to generate problem-related documents | ||||||||||||
| GenRead | 42.2 | 49.4 | 70.8 | 74.8 | 41.3 | 48.5 | 38.0 | 43.2 | 67.3 | ---- | ---- | ---- |
| GenRead + ProCo | 48.3 | 55.6 | 78.4 | 82.4 | 46.7 | 53.9 | 47.0 | 51.0 | 76.4 | ---- | ---- | ---- |
| *Using search engines to retrieve problem-related documents | ||||||||||||
| RAG | 45.3 | 52.4 | 72.7 | 76.4 | 40.1 | 46.9 | 37.0 | 41.1 | 65.9 | ---- | ---- | ---- |
| RAG + ProCo | 48.5 | 56.0 | 78.4 | 82.1 | 45.2 | 52.5 | 39.0 | 44.2 | 74.2 | ---- | ---- | ---- |
| *Direct question answering without external documents | ||||||||||||
| CoT | 40.3 | 46.4 | 69.2 | 72.2 | 38.2 | 44.6 | 28.0 | 31.2 | 72.9 | 78.6 | 51.3 | 37.9 |
| Self-Correct | 40.1 | 47.1 | 71.3 | 74.1 | 39.2 | 45.7 | 29.0 | 32.4 | 65.9 | 75.1 | 48.7 | 27.6 |
| CoVe | 43.4 | 48.9 | 76.4 | 79.4 | 43.1 | 49.0 | 31.0 | 35.2 | 73.1 | ---- | ---- | ---- |
| ProCo | 48.0 | 54.8 | 78.7 | 82.1 | 47.0 | 57.0 | 33.0 | 36.2 | 75.5 | 87.1 | 65.2 | 41.5 |
Performance on NQ, TriviaQA, WebQ, HotpotQA, CSQA, GSM8K, AQuA, and MATH benchmarks using GPT-3.5-Turbo-1106 (black-box LLM) and Mixtral-8x7B (open-source LLM). The best performance for each dataset is highlighted in bold. ProCo improves baseline methods with external documents across all benchmarks and outperforms those without external documents.