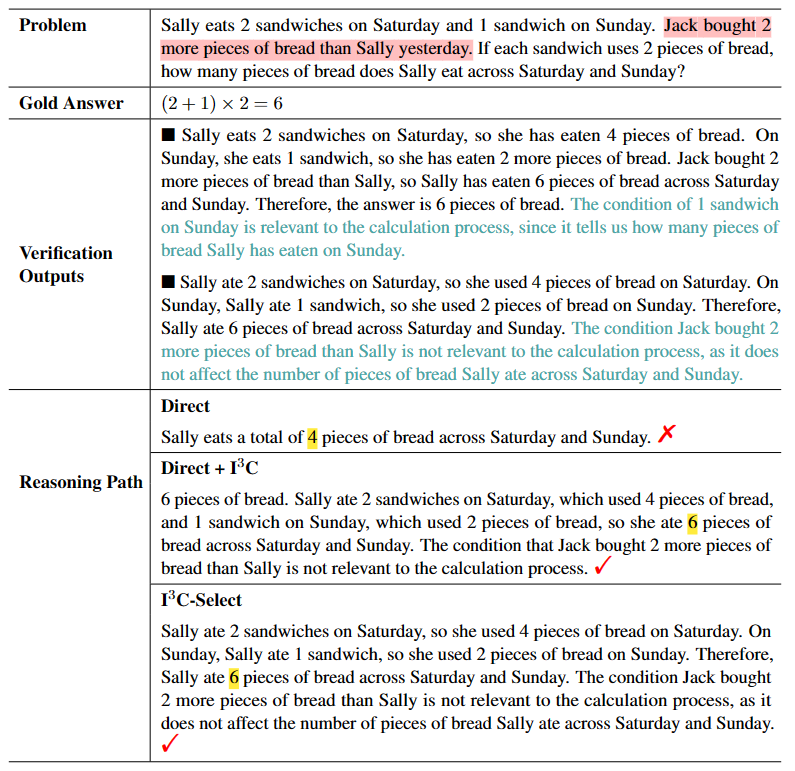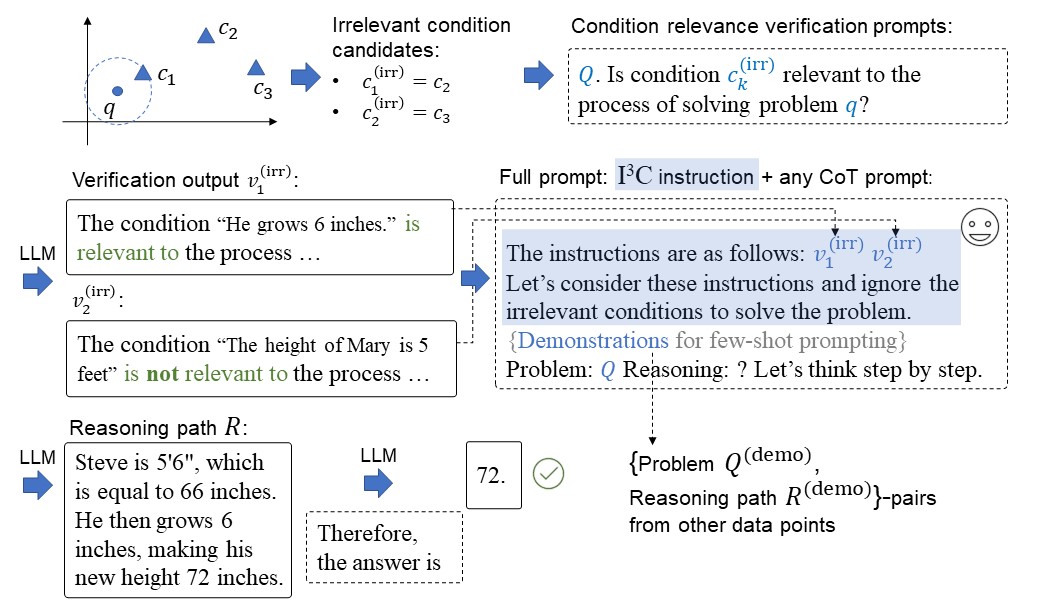
We use eight math word problem (MWP) datasets as our testbed. AddSub, SingleEq, SVAMP, and GSM8K are classical MWP datasets in which some of the problem descriptions contain irrelevant conditions. GSM-IC2-1K and GSM-ICM-1K are challenging datasets that require multi-step reasoning, and each problem description contains irrelevant conditions. AQuA and MATH are more challenging datasets that contain problems from high school competitions. We compare our proposed I3C-Select prompting method with two types of prompting baselines: (1) Zero-shot baselines. We include Zero-Shot-CoT, PS, Instruct-CoT, and Direct. The Direct baseline uses the prompt "The answer is" to get the final answer. (2) Few-shot baselines. We include Manual-CoT, Complex-CoT, PAL, and Auto-CoT. The demonstrations of these baselines are from their original papers.
| GPT-3 (text-davinci-003) | AddSub | SVAMP | GSM8K | SingleEq | GSM-IC2-1K | GSM-ICM-1K | AQuA | MATH |
| Direct | 89.3 | 65.2 | 15.0 | 84.6 | 22.8 | 9.0 | 28.7 | 7.6 |
| Direct + I3C | 92.4 (+3.1) | 74.5 (+9.3) | 49.7 (+34.7) | 92.7 (+8.1) | 82.6 (+59.8) | 66.9 (+57.9) | 36.2 (+7.5) | 11.3 (+3.7) |
| Zero-Shot-CoT | 84.8 | 74.3 | 60.8 | 89.5 | 70.7 | 62.5 | 40.5 | 12.4 |
| Zero-Shot-CoT + I3C | 91.7 (+6.9) | 75.9 (+1.6) | 61.3 (+0.5) | 93.7 (+4.2) | 84.7 (+14.0) | 71.4 (+8.9) | 45.7 (+5.2) | 17.9 (+5.5) |
| PS | 88.1 | 72.0 | 58.2 | 89.2 | 70.9 | 63.5 | 38.1 | 13.7 |
| PS + I3C | 91.4 (+3.3) | 75.6 (+3.6) | 61.1 (+2.9) | 93.1 (+3.9) | 84.8 (+13.9) | 69.4 (+5.9) | 43.6 (+5.5) | 18.2 (+4.5) |
| Instruct-CoT | 90.4 | 76.3 | 57.8 | 91.1 | 82.4 | 64.3 | 44.5 | 16.1 |
| Instruct-CoT + I3C | 91.8 (+1.4) | 77.0 (+0.7) | 61.0 (+3.2) | 92.7 (+1.6) | 84.7 (+2.3) | 71.3 (+7.0) | 46.3 (+1.8) | 21.3 (+5.2) |
| Manual-CoT | 87.8 | 76.7 | 56.9 | 91.3 | 73.9 | 60.6 | 44.0 | 15.6 |
| Manual-CoT + I3C | 92.9 (+5.1) | 80.1 (+3.4) | 61.6 (+4.7) | 93.9 (+2.6) | 82.0 (+8.1) | 66.1 (+5.5) | 49.1 (+5.1) | 19.8 (+4.2) |
| Auto-CoT | 90.6 | 77.8 | 58.9 | 90.9 | 74.3 | 65.2 | 47.2 | 16.3 |
| Auto-CoT + I3C | 93.7 (+3.1) | 80.0 (+2.2) | 61.9 (+3.0) | 93.5 (+2.6) | 83.9 (+9.6) | 68.2 (+3.0) | 51.5 (+4.3) | 22.5 (+6.2) |
| Complex-CoT | 88.9 | 78.0 | 67.7 | 92.7 | 75.3 | 66.5 | 48.8 | 17.4 |
| Complex-CoT + I3C | 92.8 (+3.9) | 80.0 (+2.0) | 70.6 (+2.9) | 94.0 (+1.3) | 87.1 (+11.8) | 83.6 (+17.1) | 53.2 (+4.4) | 23.1 (+5.7) |
| I3C-Select (Ours) | 93.9 | 80.3 | 72.6 | 94.3 | 93.7 | 90.9 | 57.1 | 28.5 |
Accuracy (%) comparison on eight MWP datasets. I3C indicates that instructs LLMs to identify and ignore irrelevant conditions. Adding the I3C instruction to CoT prompting methods effectively improves performance. Selecting the most confusing problems and their generated reasoning paths as demonstrations for few-shot learning (i.e., I3C-Select) achieves state-of-the-art performance on all eight MWP datasets.